AI越勤快,会话死得越快:一个被90%开发者忽视的架构盲区
如果你每天都在用Cursor、Claude Code或者类似的AI编程工具写代码,有没有遇到过这种诡异的情况:
一开始,AI像个得力助手,理解你的意图,给出精准的代码。聊了十几轮后,它开始“失忆”——忘了刚才定义的函数,忽略了你反复强调的约束条件,甚至犯一些低级错误。
你以为是AI变笨了,开个新会话,它又生龙活虎。
问题出在哪?不是你,也不是模型,而是一个被绝大多数人忽视的元凶:Context Window(上下文窗口)被工具调用“撑死”了。
今天,我们来拆解一个AI工程领域的底层问题——当工具越来越勤快,你的会话为什么死得越来越快?以及,一个叫“Context Mode”的方案,试图如何解决这个问题,它又暴露了哪些更深层的架构盲区。

01. 隐形杀手:工具越勤快,会话死得越快
先看一组真实数据:
一次Playwright截图测试,五万Token没了。 一次git log查询,一万五千Token没了。 三四个工具连着调,十万Token瞬间蒸发。
而主流模型的Context Window也就二十万左右。这意味着,你什么都还没干,光是让AI跑了几轮工具,上下文就快满了。
问题出在哪?每次工具调用,原始数据都是“洪水式”涌入。
你让AI跑个测试,你只需要知道三件事:通过了没有?哪行失败了?什么错误信息?但进入Context的是什么?是完整的测试日志——所有通过用例的细节、失败的堆栈追踪、环境变量、时间戳……90%的Token,花在了你根本不需要的信息上。
结果就是:Context被日志、JSON快照、堆栈追踪填满。模型开始忘记你们十分钟前达成的共识,开始忽略你反复强调的约束。你能怎么办?只能开新会话,从头再来。
这就像一个恶性循环:你越依赖工具,工具越勤快,会话死得越快。你被迫频繁开启新会话,失去连续性,效率大打折扣。
02. Context Mode:一个“不让脏数据进门”的思路
面对这个问题,一个叫“Context Mode”的方案给出了一个极其朴素的思路:与其等数据进来了再压缩,不如一开始就不让它进来。
这个思路的核心,是三个层的设计:
第一层:沙盒隔离 工具执行被放进一个独立的“沙盒子进程”。原始输出——完整的日志、堆栈、JSON——永远不进对话历史。它们被拦在门外。
第二层:摘要+索引 什么进对话历史?只有模型真正需要的——一个简短的摘要,告诉你“测试运行完成,3个失败”。完整数据去哪了?存进本地的SQLite数据库,同时建立全文搜索索引。
第三层:按需检索 模型需要看细节?可以。但它不能直接翻原始数据,而是要通过“查数据库”的方式:发起一个搜索请求,返回精确匹配的结果。而这个搜索,不需要额外的大模型调用——SQLite内置的FTS5全文搜索引擎,加上BM25排序算法,纯算法搞定,零成本、确定性输出。同样的查询,永远返回同样的结果,对缓存极度友好。
这套设计的精妙之处在于:它把“对话历史”和“工具输出”彻底解耦了。对话历史里只有精炼的摘要和检索能力,原始数据被“藏”在外部存储里,需要时再去拿。

03. 社区智慧:从关键词匹配到混合搜索
但很快,社区里有人指出了新问题:纯关键词匹配,在结构化数据上不够好。
比如你想找“用户登录失败的处理函数”,函数名叫handleLoginFailure,关键词匹配没问题。但如果你想找“跟用户认证相关的错误处理”,没有精确的函数名,只有语义概念,关键词就抓瞎了。
于是有人做了混合方案:
- FTS5全文搜索:负责精准匹配函数名、变量名、报错信息
- 向量搜索:负责语义理解,找到“概念上相关”的内容
- RRF融合排序:把两种结果按权重混合,取长补短
他用这套方案索引了一万五千多个文件,效果出奇的好。既保留了关键词的精确性,又获得了语义的灵活性。
这个思路其实揭示了一个趋势:AI的记忆系统,正在从“纯模型记忆”走向“混合检索增强”。 模型负责理解意图和生成回复,但具体的数据存储和检索,交给专门的、确定性的系统。
04. 一个硬伤:MCP协议下的漏网之鱼
但Context Mode有个硬伤——它只能拦截“内置工具”。
如果你用的是内置的测试运行器、文件读写工具,没问题,沙盒隔离生效。但如果你用的是第三方MCP工具,完全无效。
为什么?因为MCP(Model Context Protocol)工具的响应,是通过JSON-RPC直接发给模型的,中间没有任何可以“拦截”的钩子。MCP工具返回大量数据时,Token照样吃,Context照样满。
这个问题,靠客户端解决不了。只能靠MCP开发者在服务端做优化——在工具设计层面,就考虑如何精简输出,如何支持按需检索。但在那之前,MCP生态的用户,只能眼睁睁看着Token被吃掉。
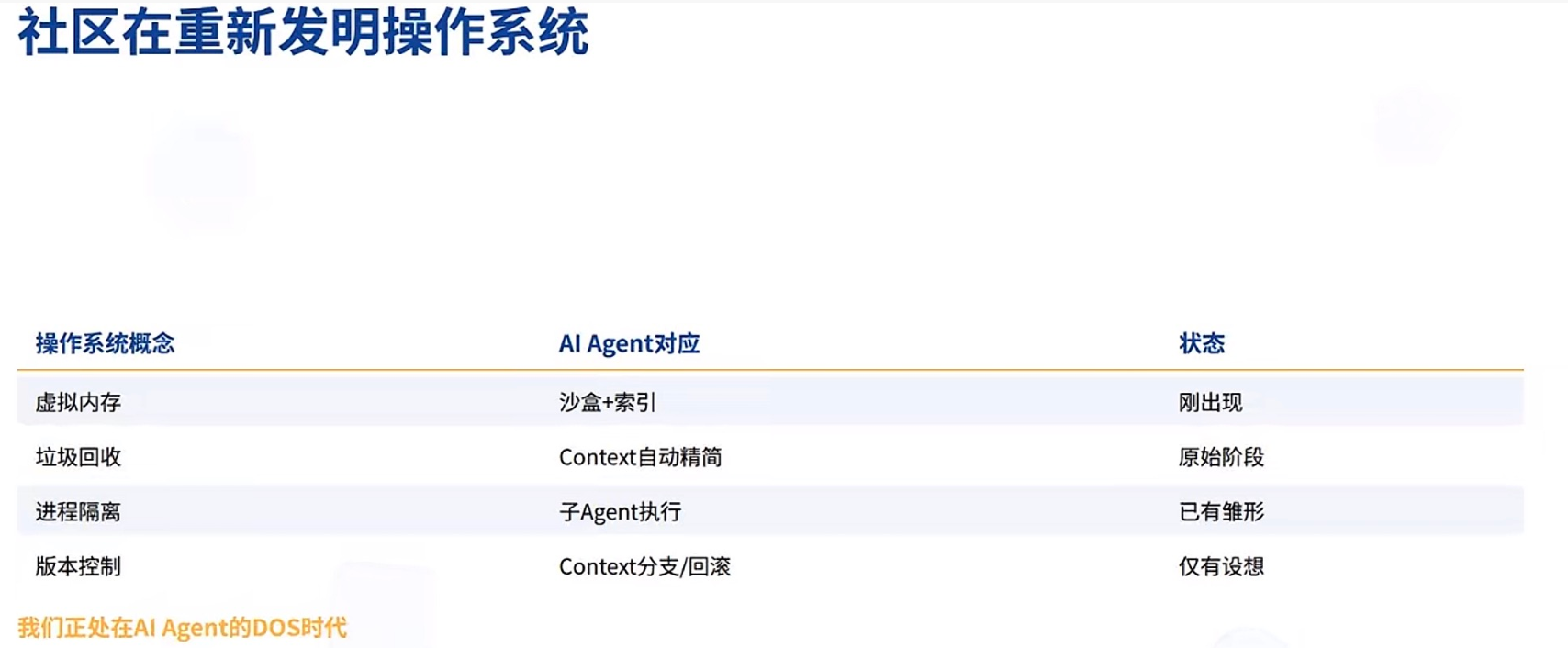
05. 比方案更重要的:我们正处在AI Agent的“DOS时代”
但今天聊这些,不是为了安利某个具体方案。更值得思考的是:这件事揭示了什么底层规律?
它让我想起操作系统早期。
那时候内存稀缺,程序直接操作物理内存。内存装不下?程序就崩溃。开发者每天都在跟内存极限搏斗。
后来有了虚拟内存。程序以为自己有无限内存,操作系统在背后默默做换入换出。开发者不用再操心物理内存够不够,可以专注于业务逻辑。
现在,Context Window就是新内存。
今天,工具输出直接灌进Context,满了就降智、就崩溃。开发者被迫频繁开新会话,手动管理Context,就像当年手动管理内存一样。
Context Mode的本质是什么?就是AI Agent的虚拟内存。
- 沙盒隔离 → 进程隔离
- 摘要+索引 → 内存换出
- 按需检索 → 缺页中断
社区里有人提了更激进的设想:Context应该像git一样,支持分支、回滚、合并。这个想法如果实现,你可以在一个会话里试错、回退、开分支探索新思路,再合并回来。Context不再是线性消耗品,而是一个可管理的状态系统。
这些想法印证了一点:我们正处在AI Agent的DOS时代。 基础设施还极其原始,开发者还在跟内存极限肉搏,工具链还在各自为战。

06. 对AI工程师的三个启示
如果你正在开发或深度使用AI Agent,这个故事至少有几点值得琢磨:
第一,Context管理不是优化问题,是系统设计问题。
你不会等到程序内存溢出了,才开始想“要不要加个虚拟内存”。同样,你也不该等到会话降智了,才抱怨“模型太笨”。在设计Agent架构时,就该想清楚:数据在Context里的生命周期是怎样的?哪些数据必须进会话?哪些可以放外部?如何支持按需检索?
第二,MCP协议有结构性缺陷。
它假设“工具返回的数据可以直接给模型”。但现实是,工具输出远超模型需要。这个假设正在让MCP生态走向“Token浪费”的死胡同。MCP需要一层“输出网关”——在数据到达模型之前,先做压缩、摘要、索引。这层基础设施,目前还是空白。
第三,最大的机会不在“写Agent”,而在“Agent基础设施”。
Context管理、记忆系统、状态持久化、工具输出网关——这些都是AI Agent的操作系统层。写Agent的人很多,做Agent OS的人很少。而平台层的价值,永远大于应用层。
写在最后
Context就是新时代的内存。
我们今天讨论的“工具调用撑爆会话”,不是某个模型的缺陷,也不是某个工具的bug,而是整个AI Agent生态在早期阶段必然经历的“内存管理危机”。
就像操作系统从物理内存走向虚拟内存,从手动管理走向自动回收,AI Agent也正在经历类似的进化。Context Mode、混合检索、输出网关——这些零星的探索,拼凑起来,就是Agent操作系统的雏形。
这个领域,还远未成熟。而成熟之前,永远是机会最多的时候。
如果你在用AI编程工具,有没有遇到过“会话越用越笨”的情况?你是怎么解决的?欢迎在评论区聊聊你的经验。
全部回复(0)
暂无回复,欢迎发表第一条评论。