一个看似不可能动刀的千年基座,被Kimi用“旋转90度”的神来之笔彻底重构
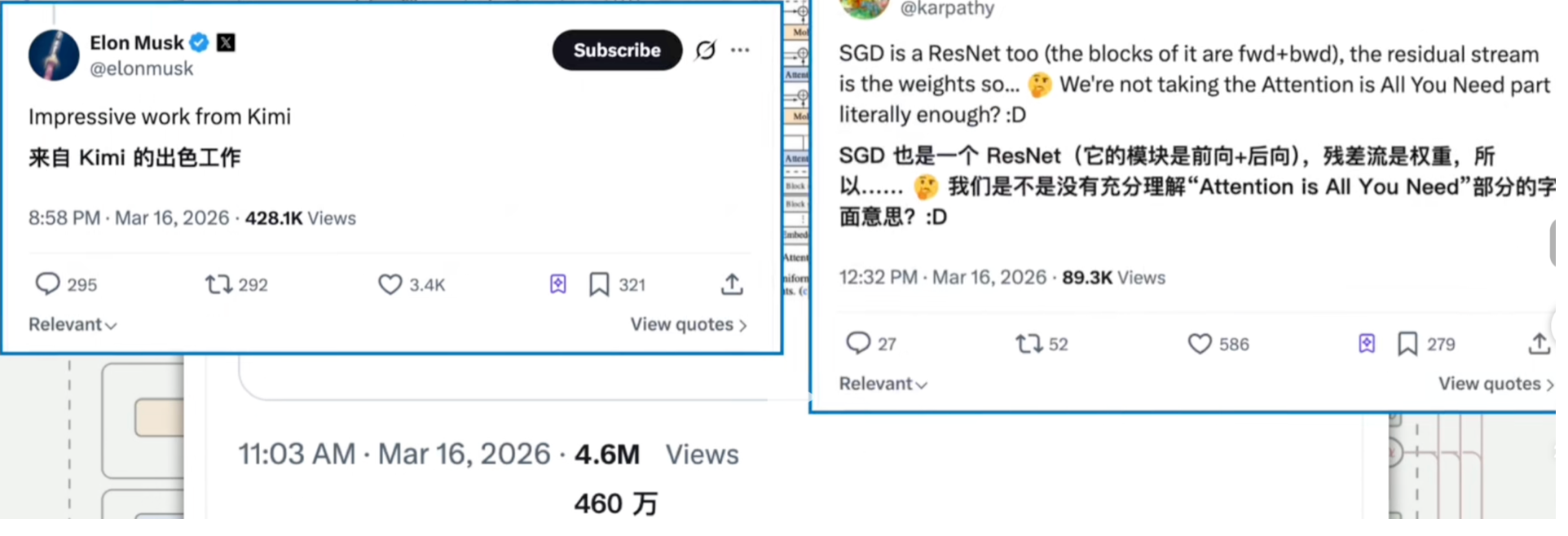
这几天AI圈最火的话题,非Kimi的注意力残差莫属。
一篇技术论文,在X上狂揽近500万浏览量,连马斯克、卡帕西这样的顶级大佬都忍不住驻足围观。国内微信搜索指数突然激增。
与此同时,Kimi的估值在不到3个月内翻了近4倍,飙升至180亿美元。听说新一轮10亿美元的融资也正在路上。

画面中,Kimi创始人在GDC大会上分享着这项引爆全球的技术创新。弹幕里飘过无数个问号:注意力残差到底是个啥?什么叫把残差旋转90度?为什么卡帕西说“重新认识Attention is all you need”?
问题有点多,但别担心。今天,我带你把Kimi这个底层架构的创新彻底打通关。
拆解那些神级大佬的评论,看看他们是怎么敢在这个千年不变的大模型基座上动刀的。看完这篇文章,你一定能在技术之美中感受到那种拍案叫绝的震撼。
老规矩,清空大脑,跟我一起进入这场探索之旅。
01 从两个旋钮说起
为了捋清这一切,我们得从梯度这个概念说起。
想象你有两个旋钮——a0和a1。假如a0转一圈,a1会转0.5圈。那么这里的0.5就是梯度。说得更直白点,在只有一个变量的情况下,梯度和导数是一回事。
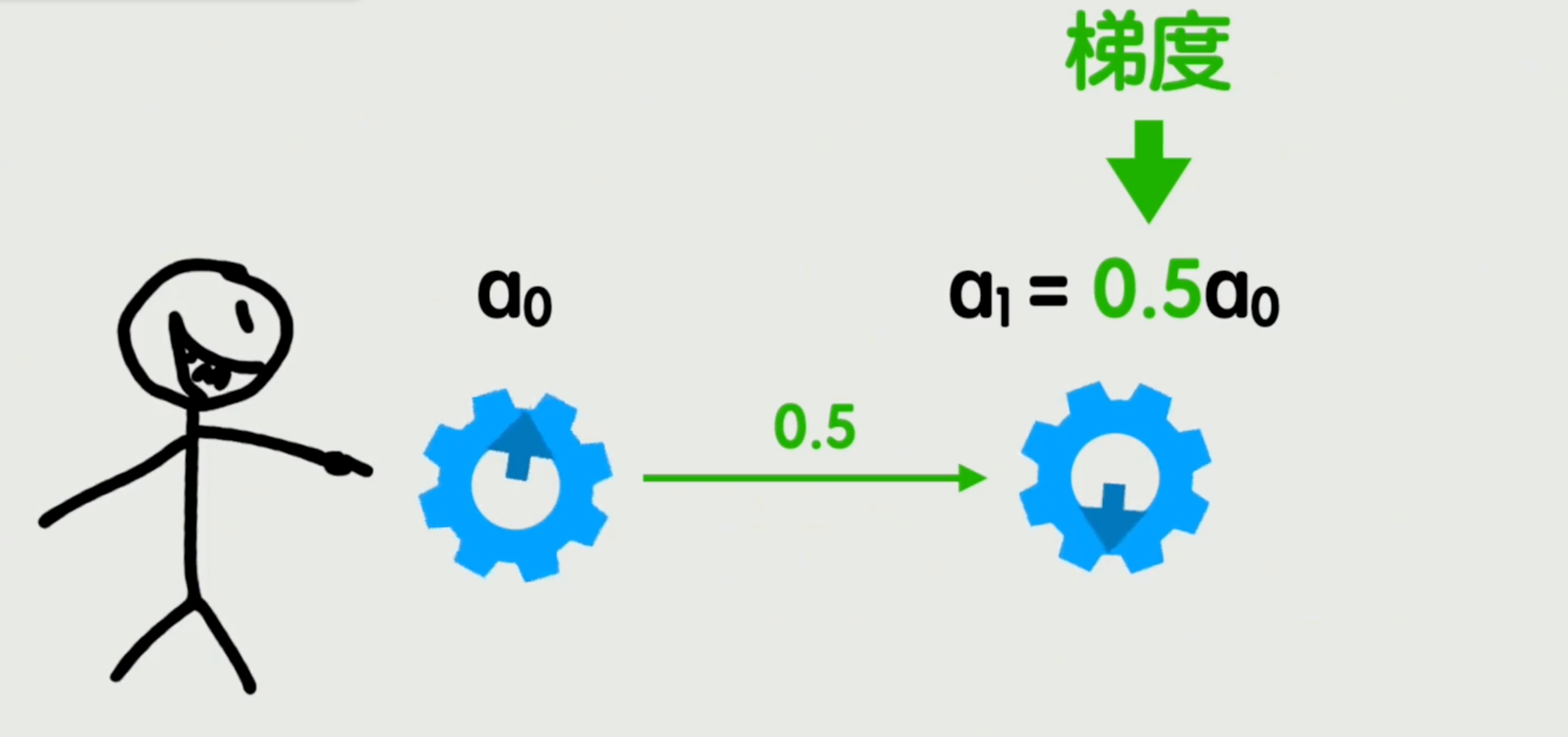
深度学习的目标也超级简单:假设蓝色旋钮代表模型参数,黑色旋钮代表损失——也就是预测数据与真实数据的误差。我们要做的,就是找到每个蓝色旋钮应该怎么转,才能让最终的损失变小那么一点点。
这个过程,就是反向传播。
但问题来了。
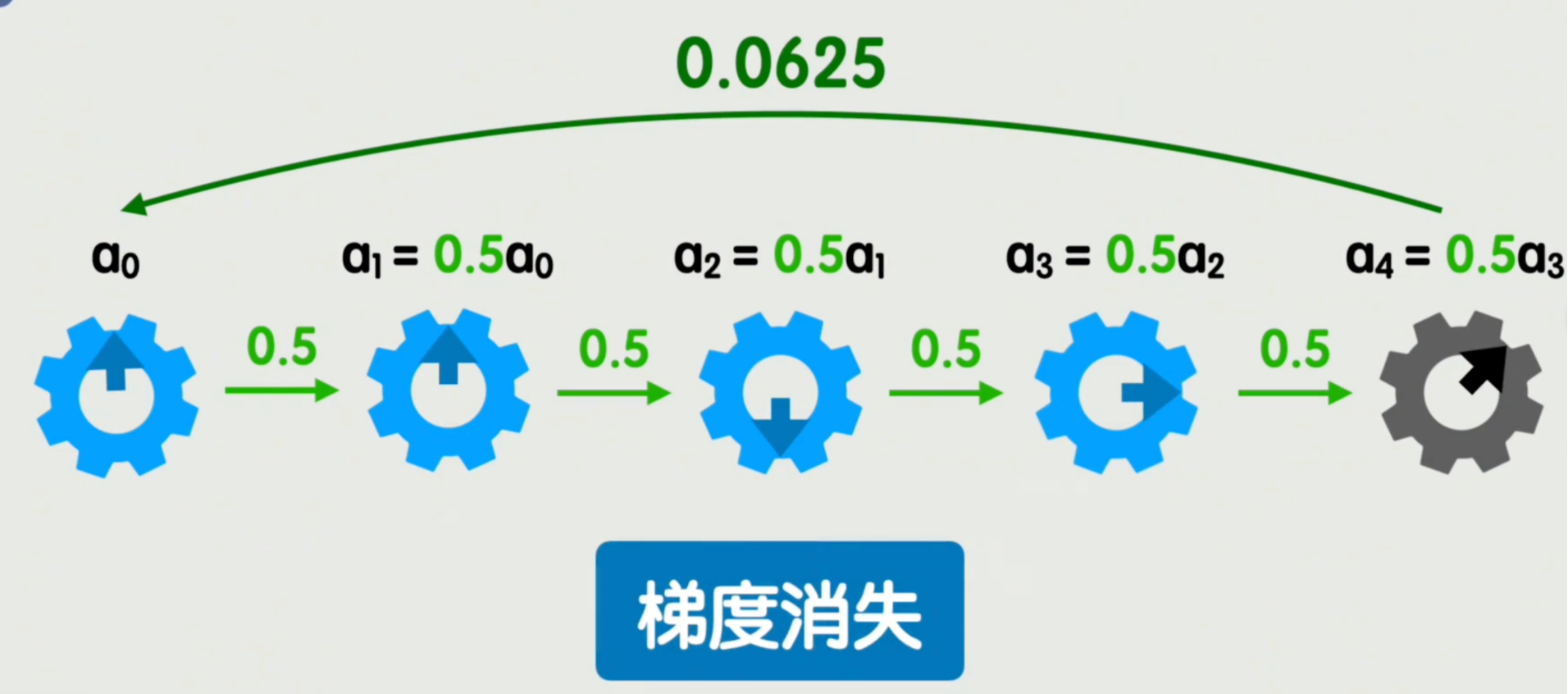
梯度会随着神经网络的层数加深,以连乘的形式不断累积。比如0.5这个梯度,连乘4次就变成了0.0625。这时,第一个旋钮转动对最后一个旋钮的影响,几乎可以忽略不计。
这就是梯度消失。
反过来,如果梯度大于1,情况就走向另一个极端。比如梯度2连乘4次,直接扩大了16倍。这时转动第一个旋钮,最后一个旋钮就直接起飞了。
这就是梯度爆炸。
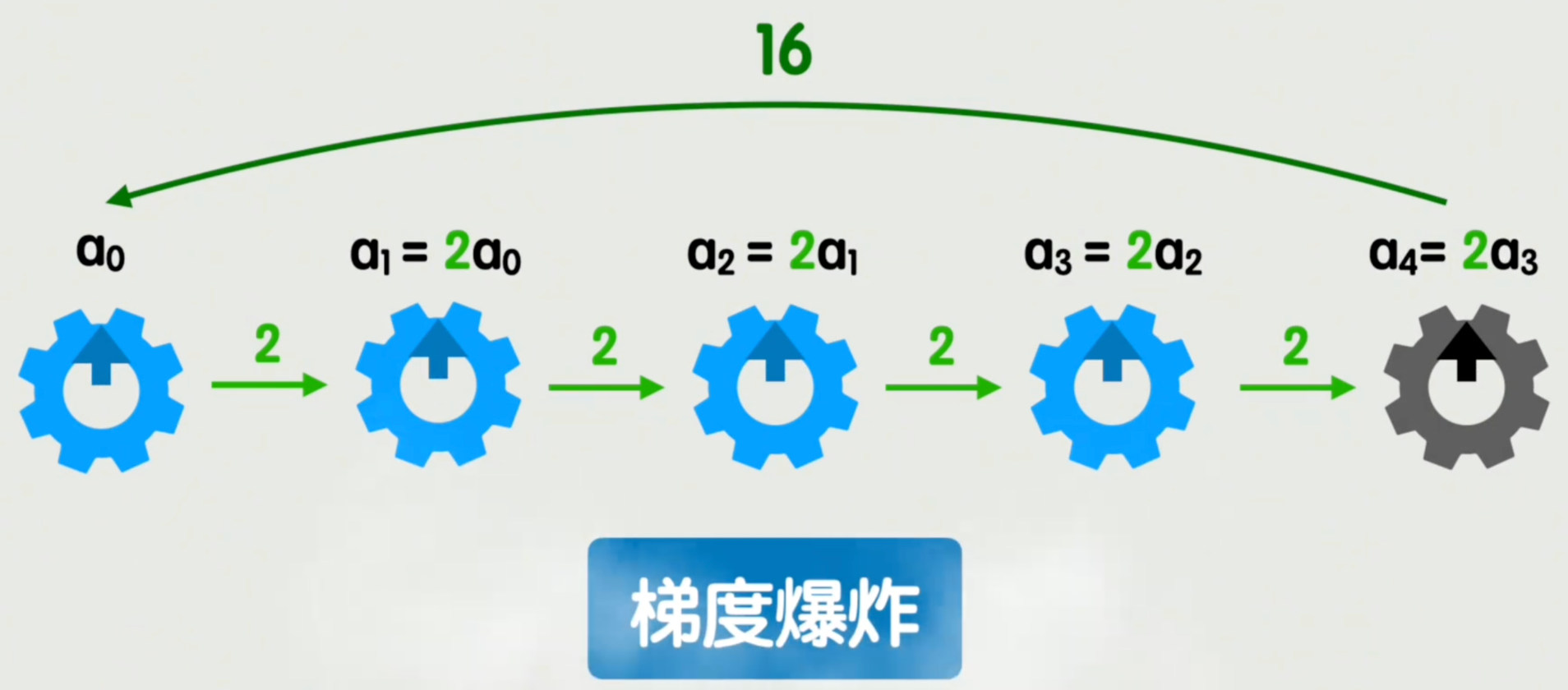
梯度消失和梯度爆炸,是影响神经网络训练稳定性的两大头疼问题。它们会让参数调整陷入不可控的恶性循环。
那么,如何解决这个问题?
02 一个“无脑”但绝妙的操作
办法其实非常简单:对于任意函数,都不管三七二十一,先把原来的输入本身加进来。
这样做带来的直观效果是:无论你的输出旋钮怎么转,都得先跟着我输入旋钮转的那一圈走。剩下的,再说。
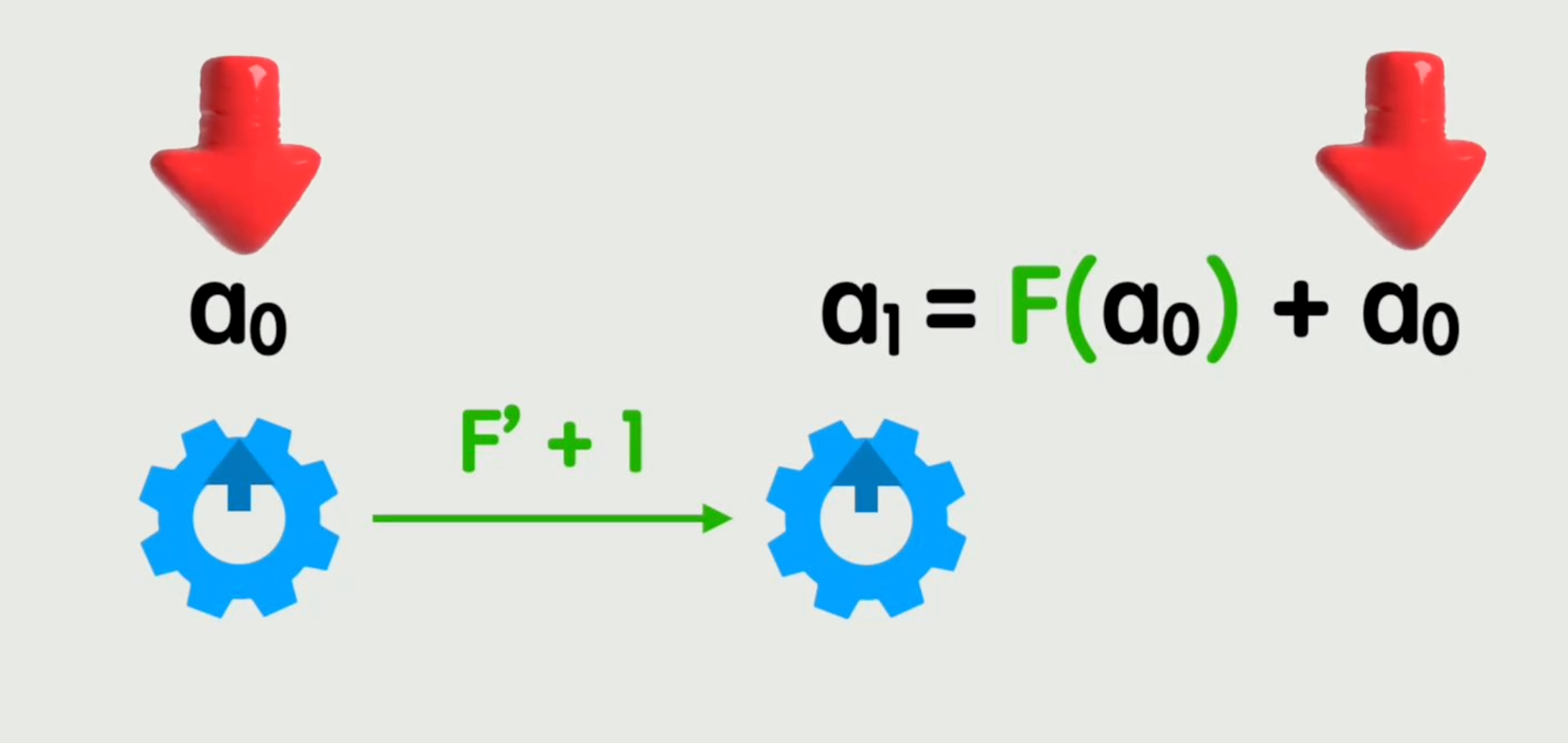
这一招极大缓解了梯度消失的问题。
改变的地方简单到令人发指——就是加了个数而已。输出和输入之间的这个差值,就叫做残差。
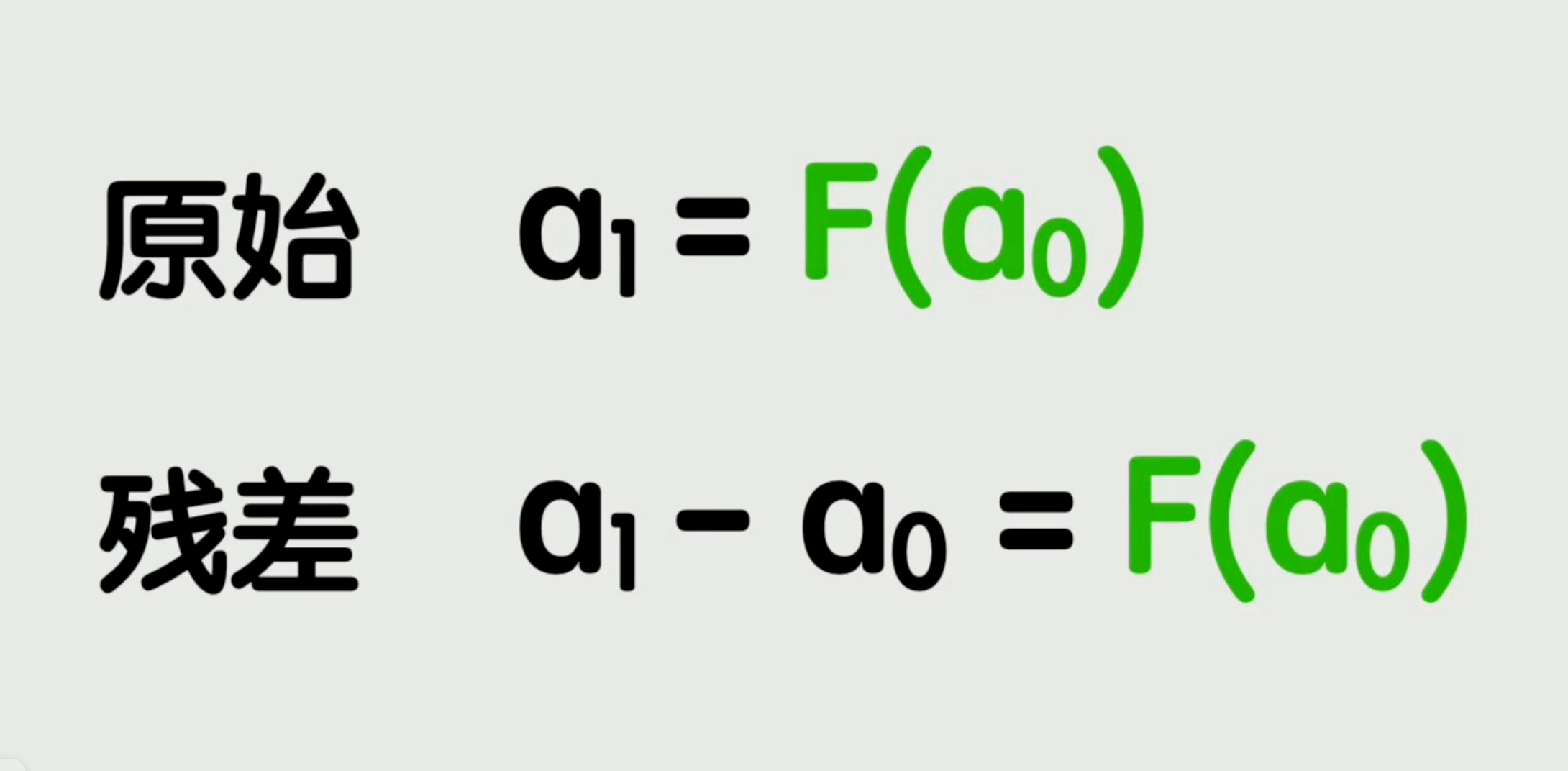
更本质地说,我们实际上是从“学习一个从输入到输出的完整映射”,变成了“只学习这个差值”。数学直觉和经验告诉我们,学习这个差值,要比学习完整映射简单得多。
这种结构画在图中通常是这个样子:这里有要学习的函数F(x),有某一层的输入x,它们加在一起构成了这一层的输出。
这就是传统的残差连接(Residual Connection)。
别看这个结构简单到几乎“无脑”,它可是从最原始的Transformer架构诞生以来就基本上没变过的基座。
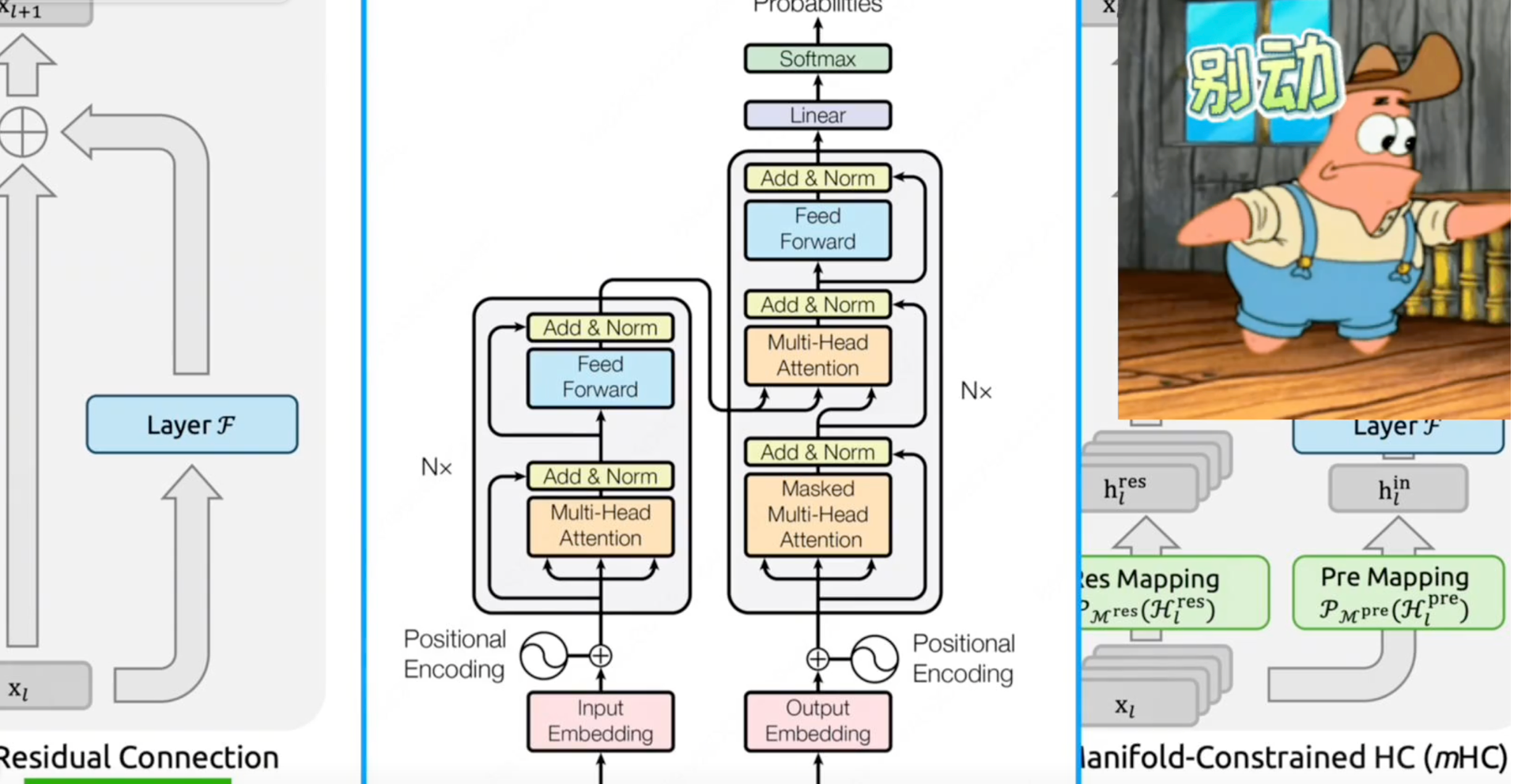
即便经历了这么多次架构革新,残差连接依然屹立不倒。因为最基础的部分,往往也是最容易被忽略的部分。久而久之,人们也形成了“它就该这样”的固有思维。
直到后来,字节跳动和DeepSeek分别提出了HyperConnection(超连接)和Muon(流行约束的超连接),第一次有人在这里动了手脚。
简单理解一下:标准残差就是每层经过一个乱七八糟的函数变换时,无脑地把之前的值加过来。这个函数可以是注意力层,也可以是MoE层,不重要,反正就相当于一个大函数。
但传统残差连接有个问题——太死板了。x1的信息传递到x4时,可能已经扭曲得不成样子了。

字节的HyperConnection提出了一个方案:拓展通道数。简单说就是把x1复制多份,同时往后也不再是简单地加过去,而是乘上一个可学习的矩阵。这样信息传递就有更多机会被保留下来。
但这个学习矩阵如果不加约束,连乘起来可能又会失控,重新引发梯度爆炸的风险。
所以DeepSeek的Muon就对这些学习矩阵加了流行约束——简单说就是让这些学习矩阵不论怎么乘,都在一个可控范围内。这其实不是个新的残差方案,而是对HyperConnection的一种改良。
但是从更宏观的视角看,不论怎么优化,这几个方法都是在做同一件事:把残差流从左到右,一层一层地加过去。
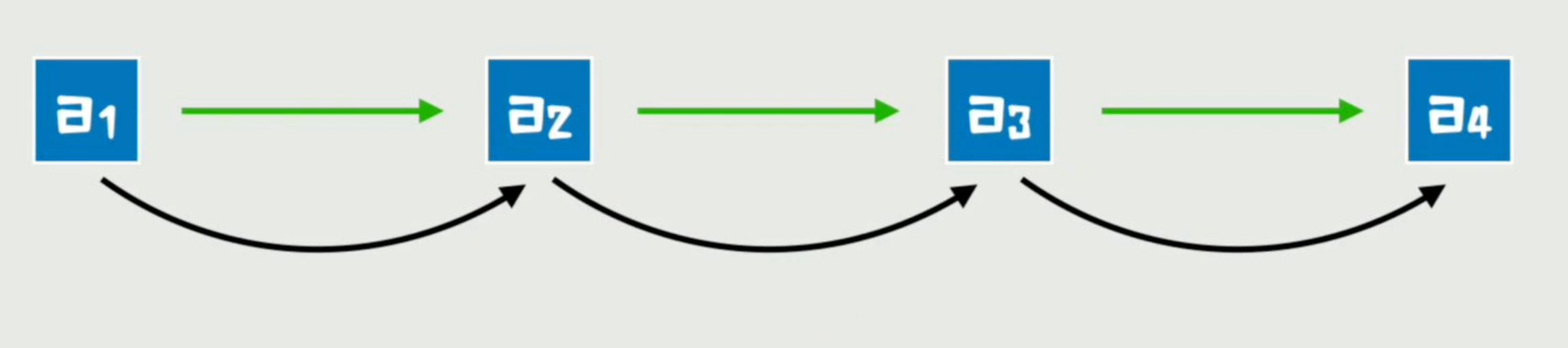
03 回忆一下,没有注意力的世界
还记不记得,在没有注意力机制的时候,语言模型是怎么工作的?
不论是RNN还是LSTM,要让每个字都包含上下文信息,办法就是从头到尾不断加过去。
正是因为这种传递方式效率实在太低,才有了后来的Transformer——现在大模型的鼻祖,基于注意力机制的架构横空出世。
它一步到位,同时把各个位置的词都拿出来进行一种加权求和。
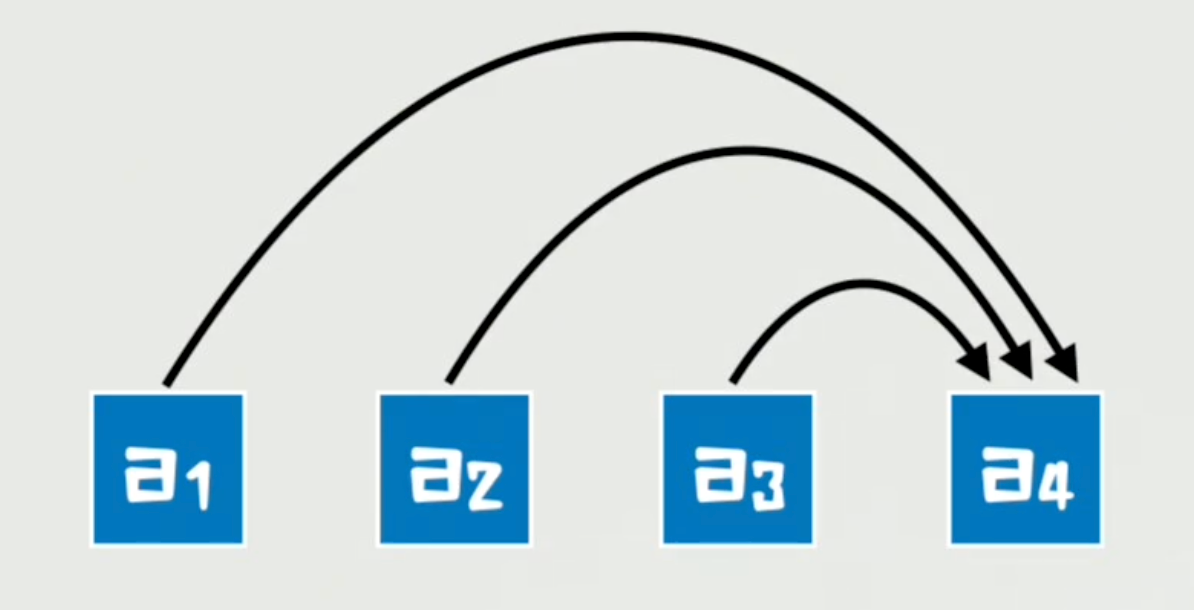
既然注意力机制在空间维度上如此成功,那么问题来了——
残差连接,是否也可以用类似的思路进行改进?
这不就巧了吗?Kimi也是这么想的。
04 旋转90度的神来之笔
用注意力来改进残差,名字也非常好起,就叫注意力残差(Attention Residuals)。
具体来说:
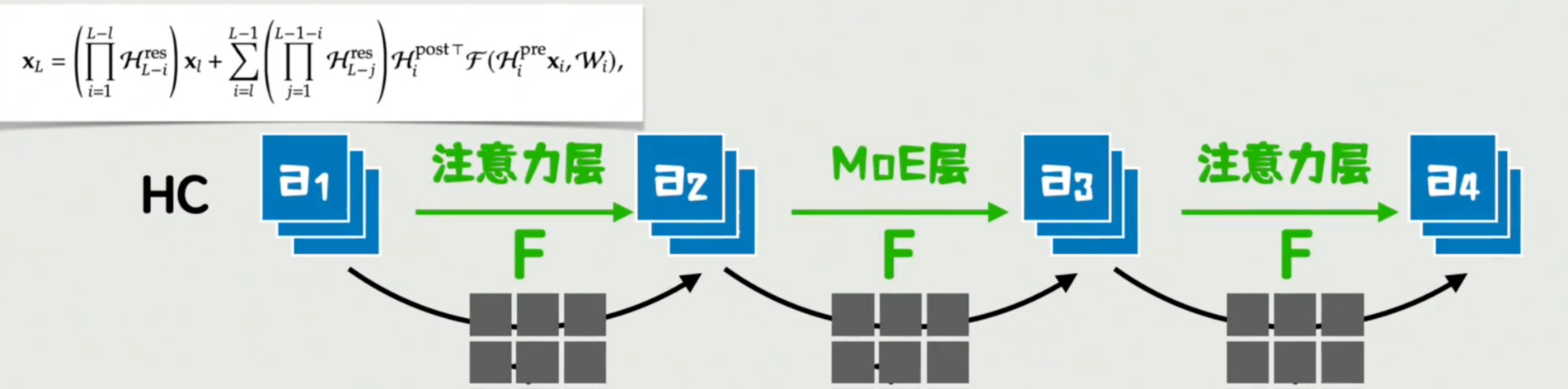
传统残差的思路,就是最左边那张图,一层一层傻乎乎地加过去。
而注意力残差,就是直接一眼看向全部,选择性地加权聚合所有前一层的输出。
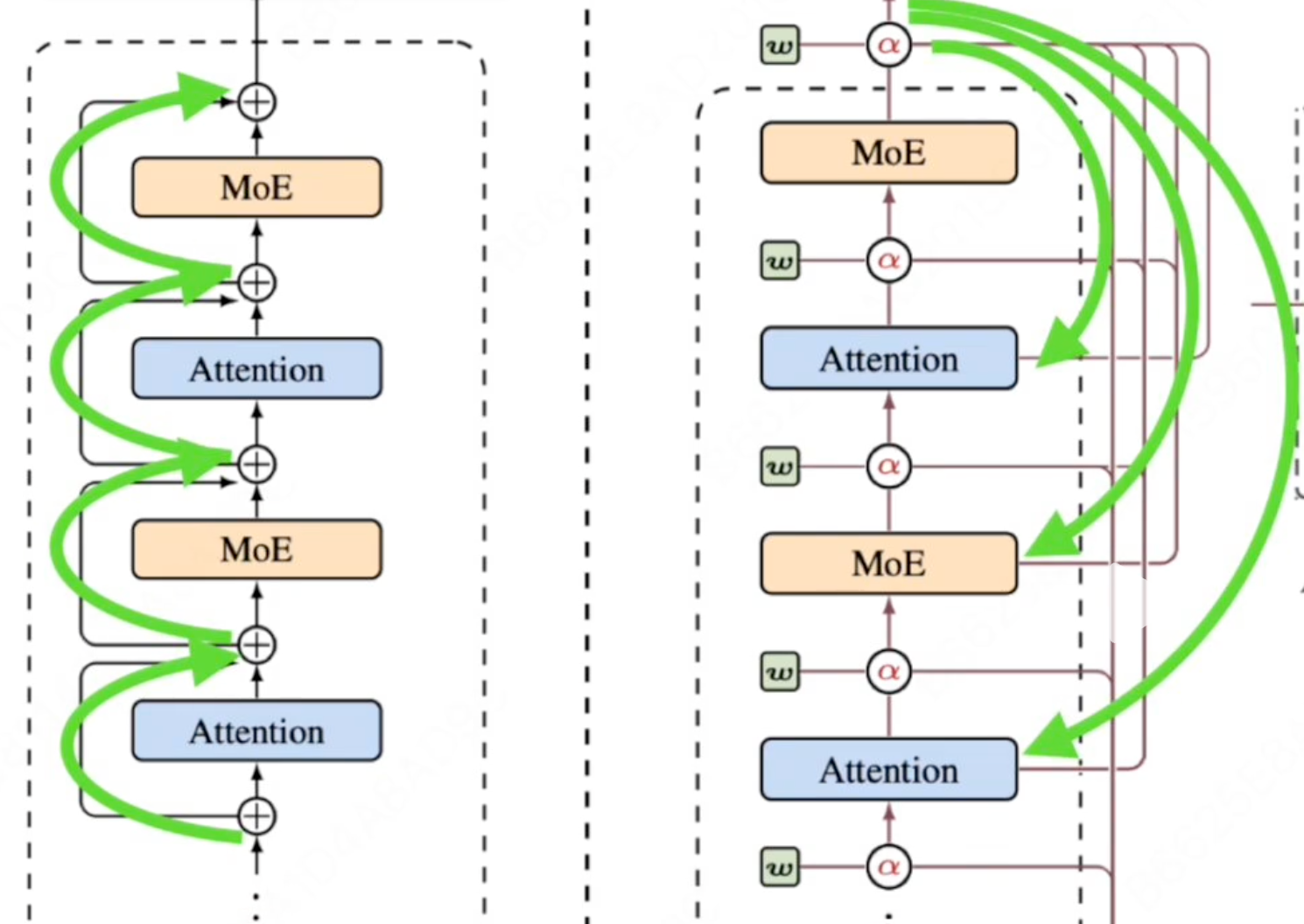
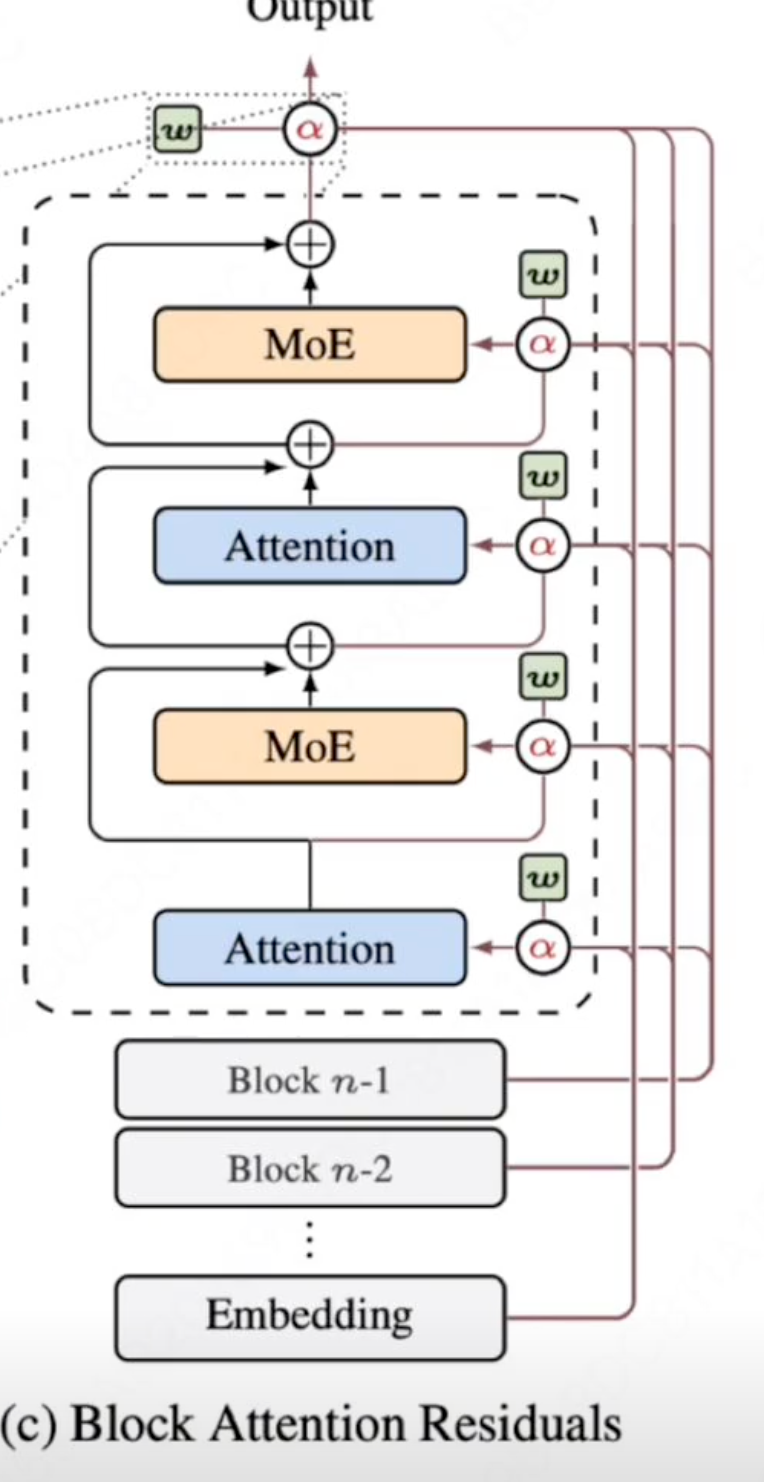
最右边那张图,是为了缓解层数太多导致的注意力计算消耗过大,而采用的分块思想——和QKV分组等思想有异曲同工之妙。
现在,跳出细节,让我们回顾一下整个演进过程:
最开始,RNN在时间维度上依次累加传递 → 变成了通过注意力机制全局加权求和 → 把它看成一个整体,就相当于在深度上做了一层注意力机制的计算 → 这就是Transformer的一层 → Transformer可以有很多层 → 残差就相当于在深度上模仿RNN在时间维度上的做法,依次累加传递。
如果想象不出来,把手机旋转90度。
实在不行,我帮你转:
这个方向上的计算方式,是不是也可以通过改成注意力机制来计算?
这就是Kimi产生注意力残差的灵感来源。
一起读一下原文中的这段话,我觉得写得非常美妙:
“时间与深度的对偶性:就像RNN在时间维度上的作用一样,残差连接在深度维度上将所有先验信息压缩成一个单一状态。在序列建模中,Transformer通过用注意力机制取代循环机制,从而改进了RNN,使得每个位置都能依赖于数据的权重,选择性地访问所有之前的位置。”
“在深度上,我们提出了同样的方法。”
这段话写得实在太美了。
再看卡帕西那条帖子的回复:
“LSTM就是将ResNet旋转90度得到的。事实证明,注意力机制同样是可以旋转90度的。”
残差流是权重?是不是没有充分理解Attention is all you need的美妙之处?

05 不止是灵感的胜利
当然,在深度学习领域,天马行空想出个什么新结构并不难。重要的是——有没有效果。
Kimi的实验结果表明确实有效:
训练效率提升了1.25倍,同等条件下各项跑分也有所提升。
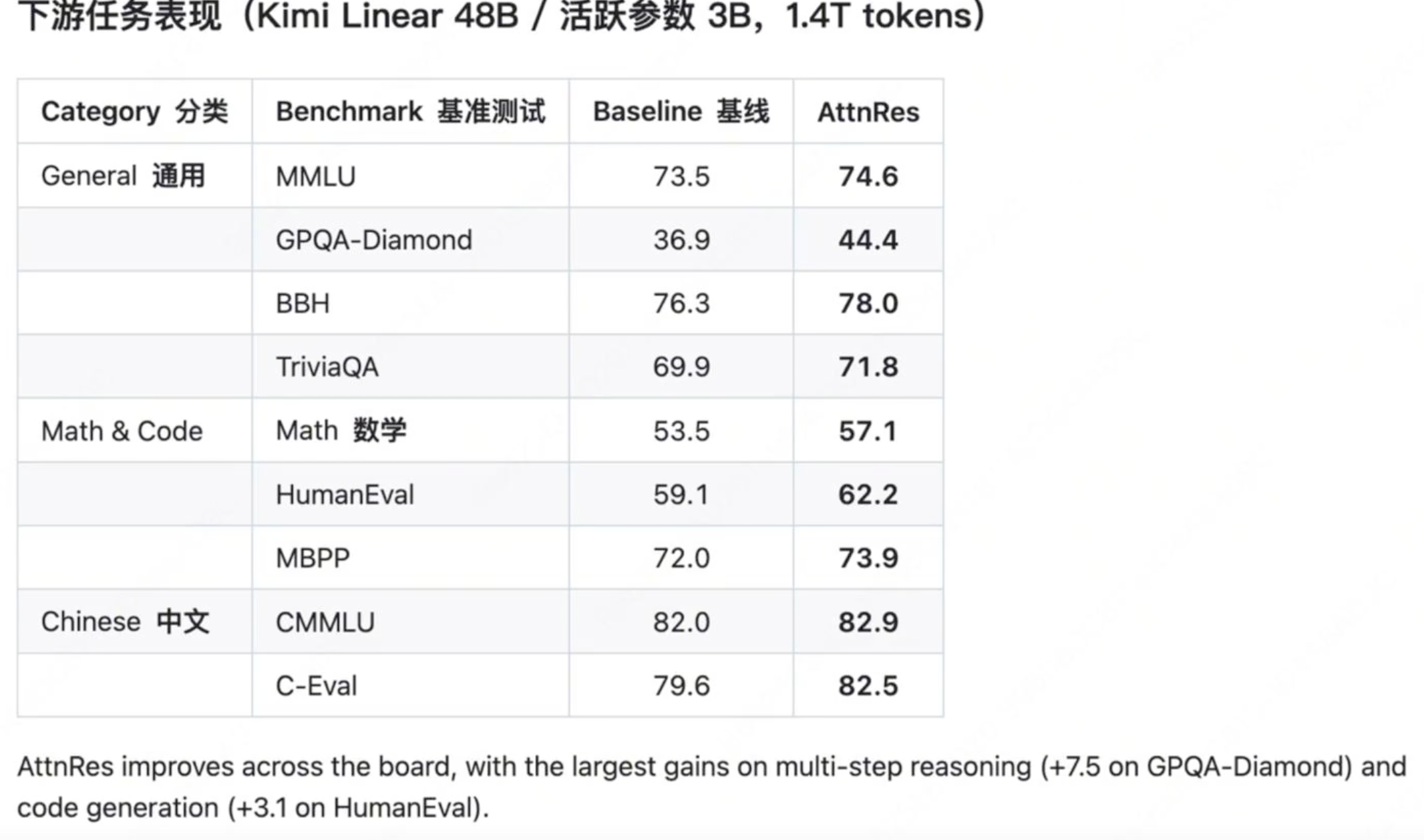
总结一下残差这个多年不变、以至于很少有人想尝试改变的“老祖宗”。近几年经历了HyperConnection、Muon,再到今天的Kimi注意力残差,变种不断涌现。
深度学习就是这样神奇。
或许客观世界真的存在一个强大而有效的模型架构,只是我们还没有挖掘出来。我们需要更多这样勇敢而富有创造力的探索和努力,一点点逼近那个或许存在、又或许不存在的真实答案。

最后,我想用卡帕西的那句话作为结尾:
“Attention is all you need——这句话,现在看来有了全新的含义。”
如果你也被这种创新的勇气打动,欢迎在评论区分享你的感受。别忘了点赞、在看、转发,让更多人看到这种打破常规的技术之美。
 非常喜欢这句话
非常喜欢这句话